

One question we often hear at conferences and industry events is whether IT organizations can get more value out of the data copies that they already have.
You bet they can. It’s been right there in front of them for a long time. As my colleague Vinny Choinski from the ESG Validation team points out, capacity efficient snapshot technology has been around for decades. It was pioneered in primary storage systems in the late 90s (e.g., EMC, IBM, Hitachi…) and got a capacity savings boost when it was combined with deduplication in data protection appliances (e.g., Data Domain) and purpose-built continuous data protection and data management solutions (e.g., Actifio). IT orgs have primarily been using these solutions for a quick and cost-effective alternative to traditional restores and some have been leveraging them to make copies for test and development. Now, backup solutions with the ability to “instantly” boot virtual machines from a writeable snapshot (e.g., Veeam) and data management solutions (e.g., Cohesity, Rubrik, Datrium) have expanded the value and the potential uses of this powerful technology, but, for most organizations, the value of these powerful technologies is a secret that’s locked up in an organizational silo. This silo is locking the value of data, limiting the return that can be realized by re-using it for additional purposes to serve the organization/business.
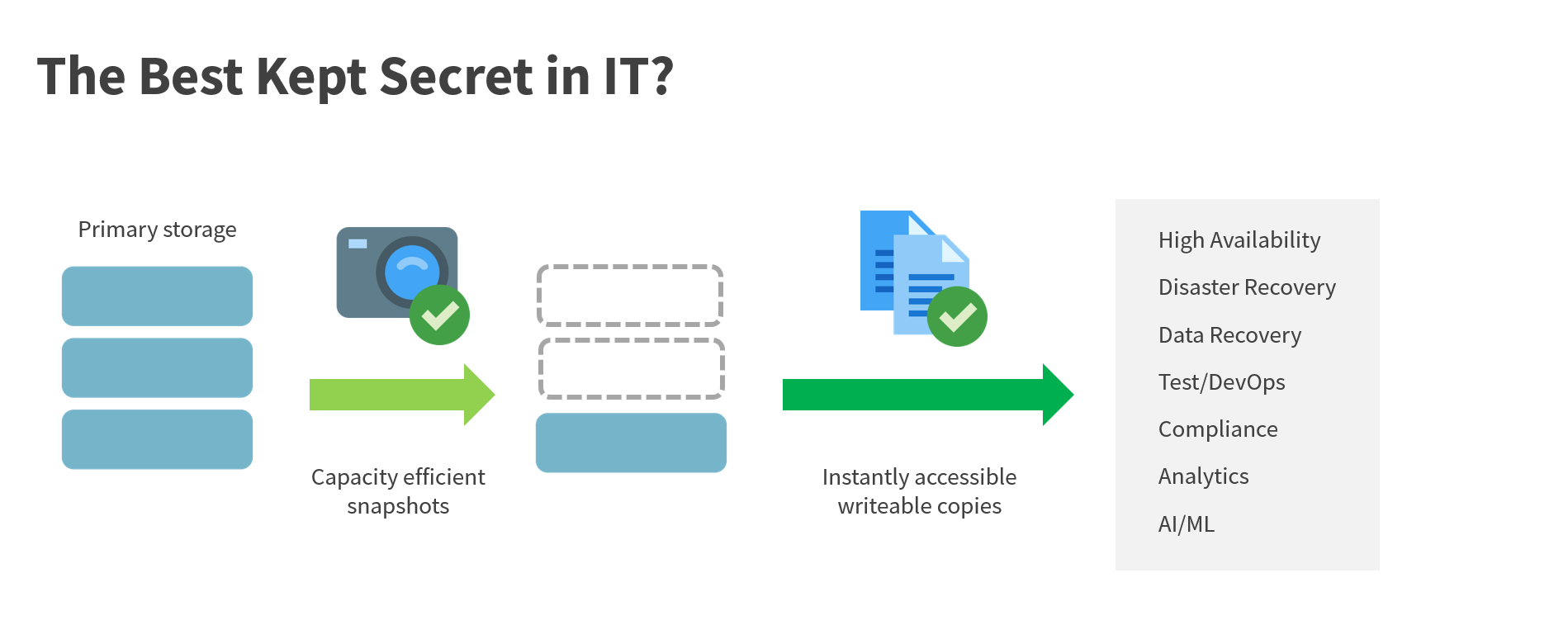 If space efficient copies are being maintained for data recovery, why not reuse the same technology to make copies for test development, compliance, analytics, AI/ML? Can the speed and ease of booting a virtual machine from a snapshot reduce the cost and complexity of high availability for business-critical applications? Can space efficient copies that are propagated to the public cloud be used for disaster recovery?
If space efficient copies are being maintained for data recovery, why not reuse the same technology to make copies for test development, compliance, analytics, AI/ML? Can the speed and ease of booting a virtual machine from a snapshot reduce the cost and complexity of high availability for business-critical applications? Can space efficient copies that are propagated to the public cloud be used for disaster recovery?
Ask around within your organization to see if any of these powerful new solutions are being used for backup and recovery or test/development. If so, ask your peers and your technology partners, “can we get more value out of the copies we already have?”
It can be done today. If you’d like to learn more about this powerful technology and “Why This Matters” to the business, check out one of the dozens of ESG Validation reports that we’ve published over the years (e.g., Catalogix, Cohesity, Commvault, Datrium, Dell, HPE, IBM, Rubrik).
This being said, there are some major caveats. While there is some granular level of understanding of what data is backed up, where it went, how old it is, etc., backup data or copied data is not always easily portable across solutions and offers very little insight into the data itself. This is where a fundamental change is happening. The requirement for context and content about the data is becoming more acute as new regulations and the need for use of data to support digital transformation are changing the role of data in the enterprise. Data has to be more intelligent to be more easily shared across an organization.
The mechanisms for data movements are clearly well understood by many IT professionals and supporting vendor solutions. The value of data is well understood by business decision makers. Let’s bring these together.
Isn’t this what one calls data management, you ask? Not so fast…Many vendors talk about data management, but no one has truly defined what this means. It really should be called “Intelligent Data Management,” meaning that beyond backup and recovery use case, the solutions or systems performing these operations can also provide insight into the data, understand the context and the content of it, and deliver management capabilities. One simple example is the classification of data, for example, knowing what you have, where it lives, performing masking operations on it, etc.
We also hear many professionals and vendors talk about “secondary” data/storage etc. It may be a confusing term in some ways: there is nothing secondary about this data for someone who runs advanced analytics and finds ways to optimize a business process, build new products, or outsmart the competition. There is truly production (“primary”) data, and what we could call “business copies” of the same data, or a subset of it. Some uses are more “technical”—for example, disaster recovery or supporting test/dev—while others are more focused on the business, like ensuring compliance or running advanced analytics.
Crossing the intelligence data management chasm is where we see the industry heading. What do you see?




